My Workflow for Reading Scientific Papers
A simple workflow that dramatically improved the way I organize and consume scientific papers and allows me to remember their content more easily.
I’ve always been interested in research. Due to my passion for security and machine learning, I’m particularly interested in security weaknesses in machine learning. In the last few years also the interest of the machine learning community in this topic has been increased dramatically and a lot of scientific literature has been published. To stay informed with the latest research trends in this area I’ve established a habit for reading research papers that are published by the machine learning community. While doing so, I have realized that without a systematic approach it’s very easy to get lost and you might end up with lots of half read papers and handwritten and digital notes distributed over various locations.
Due to that I have designed and continuously improved a workflow over the course of a few years that helps me managing and keeping track with all my downloaded papers. In this post I’d like to show you this workflow so that you can benefit from my experience.
However, as with everything in life I believe that there’s no perfect solution that fits to everyone. It’s the same with paper reading workflows. During the last years I’ve read many articles about paper reading workflows to gather ideas on how to optimize my paper reading. What I’ve seen is that all authors use different workflows. I’ve tried them and adapted them to create my own workflow. Therefore, even though the workflow I describe here works for me, it might not work for you. You may have to adjust it here and there. And even for me the workflow is not set in stone. From time to time I have to adjust this workflow for myself as well.
The focus of this article is not about how to read papers. It’s rather about managing your papers. It describes the steps I do when I see a paper for the first time until the end when I have finished reading a paper or decided not to read a paper.
Workflow
My paper reading workflow can be divided into three stages. Actually, there are four stages but the fourth stage, the review stage, is independent of the other stages so I keep it separated for now. The following diagram gives an overview of the three stages. I’m calling these stages gathering, processing and ending.

Gathering
The gathering stage is about collecting papers. Once I see a paper that might be interesting (basically papers about machine learning security), I download the paper and assign it the label #new. I use the # as prefix for labels which describes a state of a paper in one of the three stages.
To download and organize papers I use papr (see screenshot below). It’s is a simple open source command line tool which I’ve written in Python. The tool can be installed very easily via pip install papr and it allows me to download and access my papers quickly. I just start a terminal and run papr in that terminal. No browser is required, no Internet connection (in case I just want to access my papers) and no oversized (Java) application needs to be started which might consume a lot of resources and which might take some seconds before I can do anything at all.
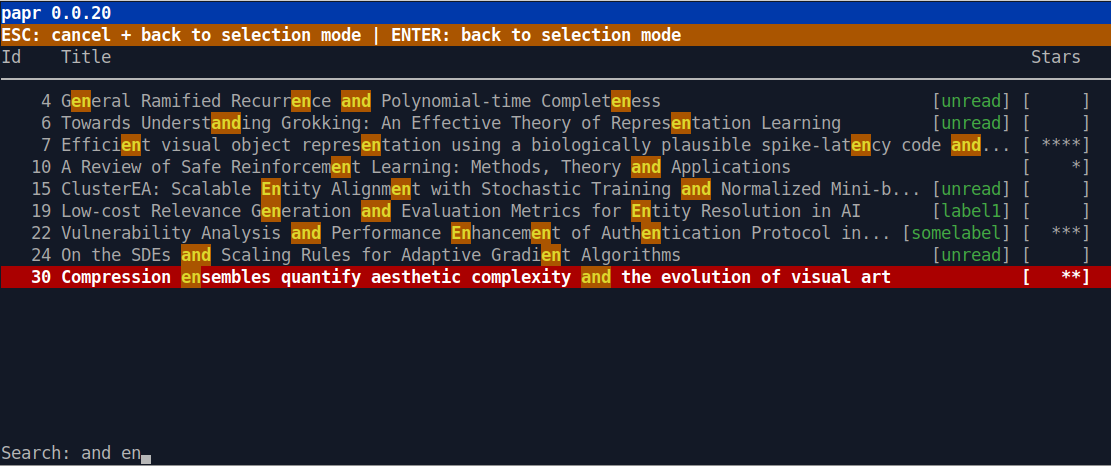
Paper Sources
I get papers from basically four sources.
My main source is arXiv. Each Friday I go to the Cryptography and Security category and look over the papers that have been published there. However, I don’t look at all papers. My focus is on papers that have also been published in the Machine Learning (cs.LG) category. To support me with this task I’ve created a simple Tampermonkey script which highlights all these papers. Additionally, this script highlights papers which contain particular keywords and papers from particular authors. I usually ignore all other papers.
In the following you can see a screenshot of papers that are highlighted by my Tampermonkey script. A paper’s title is highlighted in yellow or green if it contains a particular keyword. The subject line is highlighted in gray if it was also published in the Machine Learning (cs.LG) category.
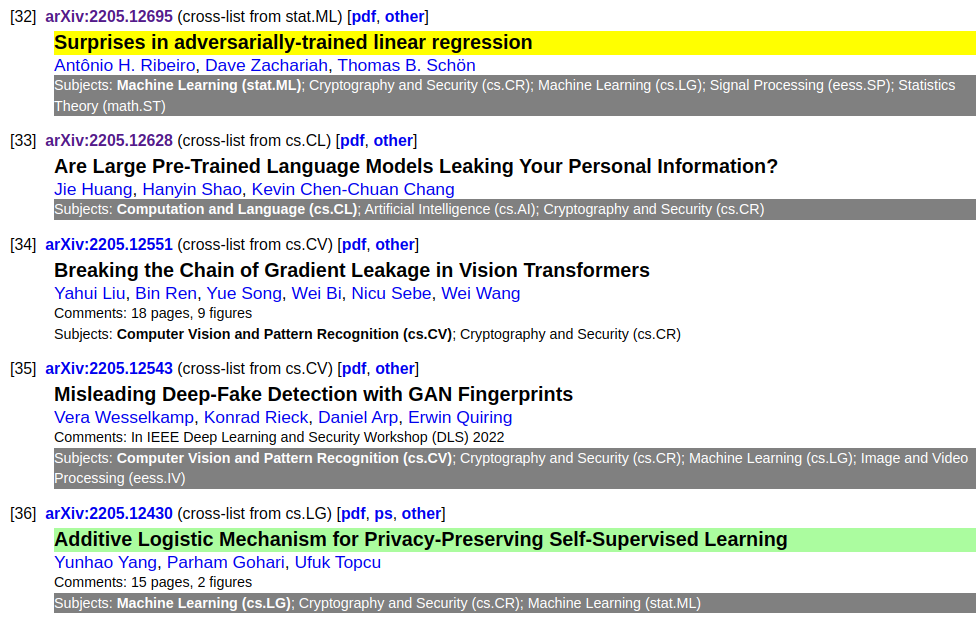
For each paper that I find interesting I copy the paper’s URL and execute papr fetch with that URL. Papr then automatically downloads the PDF from arXiv together with the abstract and other useful information about the paper. To make this step as convenient as possible I can specify multiple links at once on the command line. Furthermore, I also specify the #new label when executing papr which will be assigned to each paper once the download has finished. A typical command looks like this:
papr fetch --tags '#new' <url1> <url2> ...
Criteria for selecting papers
When selecting papers from arXiv my focus is on papers that have been accepted for being presented at conferences or for being published in journals because these papers have usually already been reviewed. I also look at the authors. If I already liked papers from an author in the past, chances are that I will also like the new paper. However, even if I use these criteria to select papers, sometimes I might also select papers which just have an interesting title or abstract.
Other sources
Even though arXiv is my main source to look for interesting papers I use some other sources as well. Papers, for instance, often contain a lot of references to other papers about the same or at least a very similar topic. Furthermore, I sometimes quickly go through the agenda of major machine learning conferences such as NeurIPS, ICML or ICLR. As the agenda of some main conferences can be quite large I often just search for some keywords that are related to my research interest. And finally, I also sometimes scan Twitter for interesting papers. However, for me Twitter is not as effective as the other sources because there’s a lot of noise on that platform.
Processing
All papers which I have found during the gathering stage are located at just one central place. This central place is papr which stores its database and all papers in a repository in my Dropbox. All new papers which I haven’t processed yet have the label #new. Due to that it’s easy to do the next step in my paper reading workflow. This step is skimming.
Skimming
In skimming I start papr and filter for all papers that have the label #new. I open one paper and start reading. Typically, I fly over the abstract, introduction and conclusion. Depending on the structure of the paper and the information that I got from these sections (or that I didn’t get), I sometimes also fly over one or two additional sections. However, I try to limit the time for skimming one paper between 5 to 10 minutes.
Even though I just fly over the text I also highlight statements from which I think that they are important for that paper. If I look a second time at that paper, these statements should help me to identify relevant parts quickly without having to skim the paper again. For highlighting on Linux I’m using Okular.
1 Sentence Summary
Once I skimmed through a paper I write a summary. My goal is to keep that summary as short as possible. Usually I write just one or two sentences.
When skimming a paper and writing a 1 sentence summary I don’t assign a new label to the paper because I try to keep the number of labels small so that the workflow becomes as simple as possible. Having too many labels would introduce unnecessary complexity. Furthermore, I usually finish both steps without interruption. So it doesn’t make sense to have labels that describe intermediate steps. For instance, I don’t stop with skimming and continue with it on another day. When I decide to skim a paper, I know that I will have enough time to finish skimming and the 1 sentence summary so that I can assign the label that comes next in my workflow when I’ve finished both steps.
As soon as I’ve completed both steps the paper gets a new label. This can be either #irrelevant (see stage Ending below) or #waiting. After assigning the new label I typically proceed with one of the following steps:
- I start skimming another paper.
- I continue reading a paper that has the label #reading.
- I start reading a paper that has the label #waiting.
- I stop and do other things.
Waiting / Reading
After skimming a paper I might come to the conclusion that I want to dive deeper into the paper. In that case I label it with #waiting. Papers with that label I haven’t yet started reading. As soon as I start reading a paper I assign it the label #reading. Due to that label I always have an overview of the papers I’m reading. The label also helps me to limit the number of papers I’m reading at the same time (I try to limit my PIP (papers in progress) to 3) and not to lose track of what I’m reading in case I will be interrupted for a longer time.
During reading I also highlight important passages and create notes. For my notes I’m using Visual Studio Code. I have configured it as my default editor in papr so that it is started when I press the key ‘n’ (for creating notes) or ‘U’ (for creating a summary) in papr.
I write my notes in Markdown because Markdown has various advantages:
- Markdown can be easily processed and scanned by command line tools such as grep.
- Markdown can be transformed in many different formats including HTML and PDF.
- Markdown is just text which can be easily managed with git.
Writing Markdown in Visual Studio Code is also quite comfortable. With the mdmath or Markdown All in One plugin I can include mathematical formulas via LaTeX syntax. The latter one also supports various keyboard shortcuts that makes editing easier and faster. For instance, you can convert a text into a link just by highlighting the text and press CTRL+v. The plugin automatically converts the highlighted text into a Markdown link (i.e. the highlighted text is put into brackets and the link into parentheses). Additionally, I’m using the Paste Image plugin that allows me to insert images (e.g. screenshots of interesting figures of the paper) into my notes via the shortcut CTRL+ALT+v.
Finalizing
Once I’ve finished reading a paper it’s time to finalize it. During the finalizing activity I perform the following steps:
Star rating
Each paper I’ve read gets between 1 to 5 stars.
Assign topic labels
Each paper also gets labels which describe the topic of the paper. To not lose track of all labels I try to minimize the number of different labels. Furthermore, to not mix topic labels with status labels, topic labels are not prefixed by the ‘#’. I also don’t assign topic labels in papr. Instead I’m using a front matter in my notes which contains a comma separated list of labels. As papr does not analyze the front matters, I have only the status labels in papr. In the example at the end of this section you can see a front matter which contains the label “object detection” and “machine learning”.
Summary
When finalizing a paper I also update the summary I’ve created during the 1-sentence-summary and add some more details that I’ve learned from the paper. I still try to keep the summary small with only the information that is necessary to quickly refresh the content of paper. To document more details I usually use the notes.
Link to other papers
I also try to connect papers with each other. For instance I connect papers that are about similar topics, papers that build on the results of other papers or which improve the results of other papers. Again, I’m using the front matter to store that information as shown below.
These links do not have to be perfect. I also do not link all papers that might be relevant. I have found that just linking some papers (and adding further links step by step during the review as described below) is already sufficient to build a relation graph that helps me to discover relevant work on a specific topic later.
Create tasks
When studying a paper I usually discover new and interesting things which I want to try out or things I want to do further research on. For these things I create tasks in a dashboard in Notion. I’m using Notion for all my tasks so that I can easily prioritize between them.
Front Matter
Each note is preceded by a front matter. This is an optional section that contains additional structured information about a paper. I’ve decided to use a front matter because it’s YAML which is an easy syntax. Many tools exist for processing YAML and you are very flexible what information you store in the front matter. For instance, you can add very easily new fields to the front matter without breaking anything.
A typical front matter which contains labels and links to other papers in my papr database is shown in the following:
---
labels: object detection, machine learning
links:
- paper: 123
labels: improvement of
- paper: 456
labels: relates to
---
Notes in Markdown are following here...
Here, the paper has the topic labels object detection and machine learning. Additionally, the paper has two links to other papers. The first link points to the paper with the identifier 123 and is an improvement of that paper. The second link points to the paper with the identifier 456 and is related to this paper.
After the front matter the notes follow written in Markdown.
Ending
After having finalized a paper or when I decided after skimming that a paper is not relevant for my interests, I assign a paper one of two possible labels in the ending stage. I set the label of a paper to #irrelevant after creating a 1 sentence summary when I came to the conclusion that a paper does not match with my interests.
On the other hand, when I have read a paper and finished the finalizing step, I assign the paper the label #done. When a paper has this label I know that I have completed the finalizing step and all its involved sub-steps.
Review
Once a week I perform a review. I would say this is the most important activity in my workflow as it helps me building a solid knowledge graph step by step and recap things I’ve learned from my paper reading.
I do not review all papers during one review slot. I’ve noticed it’s already sufficient to review only a few. I also use the timeboxing technique for the review. When I plan my week I allocate a fixed amount of time (usually 30min) for the review. Then, when I start the review, I just review as many papers as I can do during that time.
I review only papers that have the label #irrelevant or #done. During the review I read the summary and sometimes I also skim over the notes (if the paper has the label #done). I also look at the links and think about how to improve them. For instance, it can happen that I review a paper which I have processed months ago and which can be connected with a paper I’ve read recently but does not have the connection yet. If I find such a paper I add a link to the front matter.
That’s basically it when doing a review. The main goal of the review is to recap things I’ve already learned so that I don’t forget them and to improve the knowledge graph so that related information and similar concepts get connected with each other and are easier to discover when I’m looking for them.
Conclusion
Reading scientific literature such as papers is a great way to learn. However, reading papers in an unstructured way without an established workflow should be avoided. For instance, without structure it’s easy to lose the overview of all papers and interesting papers might get lost. Also, if you don’t invest the time to do a regular review, you will forget most of the things you’ve learned with high probability as most other people (especially me) do.
To avoid this I’ve developed the workflow I’ve described in this article. The workflow is nothing that I’ve created over night. It took years to develop and improve this workflow. However, even though I’m working on this workflow for years, it’s still not perfect and I regularly need to adjust it. And the reason for that is obvious. Life is constantly changing and everything around you is always changing. Therefore, it’s a logical consequence that also your workflows need to be adjusted from time to time.